When building new Ansible roles or SaaS applications for Infinito.Nexus, the same three questions come up every time: Which model fits the task? How deeply should it reason? And how do you keep the result reproducible? The following recommendation summarises a tried-and-tested approach.
Model Selection at a Glance
| Task | Model | Starting Effort |
|---|---|---|
| Simple roles following a known pattern | Sonnet 4.6 | low–medium |
| Complex roles, multi-step logic, stack debugging | Opus 4.8 | xhigh (coding), high (analysis) |
| Architecture, tricky reasoning, novel problems | Fable 5 | high, xhigh for the hardest cases |
Sonnet – the Workhorse for Standard Roles
Most roles follow established patterns: a single Docker container, a manageable tasks/main.yml, a few variables in defaults/, a Jinja template for the Compose file.
As soon as it is clear from reading the task which existing role will serve as a template, Sonnet is the right choice. It is fast and fully sufficient for well-defined, repetitive work.
Typical cases: setting up a new web app based on an existing role, renaming variables, adjusting templates, satisfying ansible-lint, or writing documentation. Deep reasoning would just be wasted compute here.
Opus – When It Goes Beyond Copy-Paste
As soon as a role demands more than “build from template”, Opus 4.8 is the model of choice – the powerful standard model for complex tasks. In a framework with centralised IAM, SSO and self-healing, this threshold is reached quickly.
Opus makes sense especially for:
- multiple services that interact – such as an app requiring both LDAP and OIDC/Keycloak integration
- demanding Jinja logic – nested templates, conditional configuration across multiple variable layers
- non-trivial dependencies – dependencies, handlers and ordering in the playbook
- cross-stack debugging – when a failure stems from the interplay of Ansible, Docker, templates and configuration
The clearest signal to switch: Sonnet loses track of the relationships between components or starts giving shallow answers.
Fable – for the Really Tough Cases
Fable 5 belongs to the Mythos class, which sits above Opus in capability. For everyday role work it is overkill, but for certain tasks it is invaluable:
- architecture decisions that affect the framework as a whole
- novel problems with no existing template in the repo
- deep refactorings across the entire codebase
- persistent bugs that have already resisted Opus
The rule here: use it deliberately, not reflexively.
Which Effort Level?
At least as important as the model choice is the effort level – meaning how much thinking budget the model uses before responding. The levels run from low through medium, high and xhigh to max; the default everywhere is high.
In Claude Code, the level is set with /effort and persists across sessions. For a single tricky step, the keyword ultrathink in the prompt deepens the reasoning for that turn only, without changing the session setting.
The recommendation per model:
- Opus 4.8: xhigh for the actual implementation (the core of role development), high for analysis and planning. Only drop to medium/low if evals confirm that quality holds – multi-step reasoning quickly suffers from effort that is too low.
- Fable 5: the default high is usually sufficient; xhigh only for the most capability-sensitive cases, as even the lower levels are strong.
- Sonnet 4.6: keep it deliberately low for schematic roles – speed is what counts here.
Two practical notes: at xhigh or max, set a generous max_tokens (64k is a reasonable starting point) so the model has room to think and act across subagents and tool calls. And if a task completes but takes noticeably longer than necessary, that is the signal to reduce effort.
Since defaults change occasionally, it is worth a quick look at the official Anthropic docs at
platform.claude.com/docsbefore important workflows.
Why Not ChatGPT / OpenAI?
Technically, Infinito.Nexus is also optimised for ChatGPT – so it works in principle. The practical reason against it is straightforward: ChatGPT burns too many tokens. The same workflow costs significantly more with OpenAI models, without producing better results. This is not a quality judgement, but an economic observation.
There is also a structural argument. Infinito.Nexus is built Claude-natively throughout – AGENTS.md, CLAUDE.md, the .claude/ directory, skills-lock.json and the entire agent workflow in the Cheatsheet all assume one ecosystem and one prompt convention. Adding OpenAI tooling in a mixed setup carries a real cost:
- fragmentation – two conventions that need to be maintained in parallel
- worse reproducibility – the requirement-to-implementation pipeline is tuned to one model family
- context-switching – friction for every contributor, which accumulates across many roles
- unclear cost control – model and effort selection as central levers only work cleanly without mixed operation
Consistency is cheaper to operate – not because one provider is better, but because it reduces maintenance and onboarding costs.
Why No Local Model (Yet)?
The obvious question: if Infinito.Nexus stands for open source, self-hosting and data sovereignty – why use a proprietary hosted model at all?
The honest answer is experience. The results with Claude integrated into OSS code editors have been noticeably better than with comparable local models. Quality, context understanding and depth of reasoning on complex Ansible roles made the decisive difference.
But this is not a closed chapter. The long-term plan is to integrate locally hosted models via Ollama with corresponding OSS IDE integrations. The goal: further accelerate development, reduce dependency on external services, and carry the self-hosting ethos more consistently into the toolchain itself. Anyone who wants to contribute experience or work on this is very welcome.
The Most Important Step: Write the Requirements Document First
Using the Cheatsheet, a new role or SaaS application can be implemented in under 24 hours – it provides ready-made copy-paste prompt templates that route an agent directly to the relevant procedure.
The decisive step, however, is not the coding itself but what comes before it: every execution starts with a suitable, detailed requirements document. It determines whether the 24 hours end in a green result or in correction loops.
The Cheatsheet flow maps this directly:
- Requirement Creation – if no requirement file exists yet, write one first.
- Requirement Implementation – only then implement the requirement end to end.
For any change with a documented acceptance scope, the implementation route is the preferred entry point; the direct development prompts are only for cases where no matching requirement exists.
In practice: invest the time upfront in a requirement that clearly defines goal, scope, acceptance criteria and constraints. Every template already starts by clarifying open requirements through active questioning and then working autonomously through to completion – a clean requirement shortens exactly that clarification phase and makes the result reproducible.
Playwright E2E Tests as a Core Component
A central element of every requirement is the end-to-end test specification based on Playwright. The requirement document must explicitly state which E2E tests need to pass for the role to be considered successfully implemented.
This is not an optional appendix – it is the foundation that enables the agent to develop according to TDD principles: the tests define the acceptance criterion, the agent implements against them, and a role is only considered done when all defined Playwright tests are green.
Typical items to specify in the requirement for the tests:
- Which pages or endpoints must be reachable
- Which login or authentication flows must work (e.g. SSO via Keycloak)
- Which core functions of the app must be operable
- Which error scenarios should be covered
If this specification is missing from the requirement, the agent has no clear target state – and the implementation ends not when the role is ready, but when the model subjectively thinks it is done. That is a significant difference.
The Strategy in One Line
- Write the requirement – always first, regardless of which model follows.
- Standard role from a template? → Sonnet, low effort.
- More complex, or Sonnet can’t keep up? → Opus, xhigh for coding.
- Architecture / uncharted territory, or Opus is stuck? → Fable.
This yields fast, cost-effective answers for the bulk of the work – and the heavy artillery is only deployed when it is genuinely needed, always built on a requirement that sets the direction.
A Final Note: AI-Centric Development – The AI as Tool, Not Master
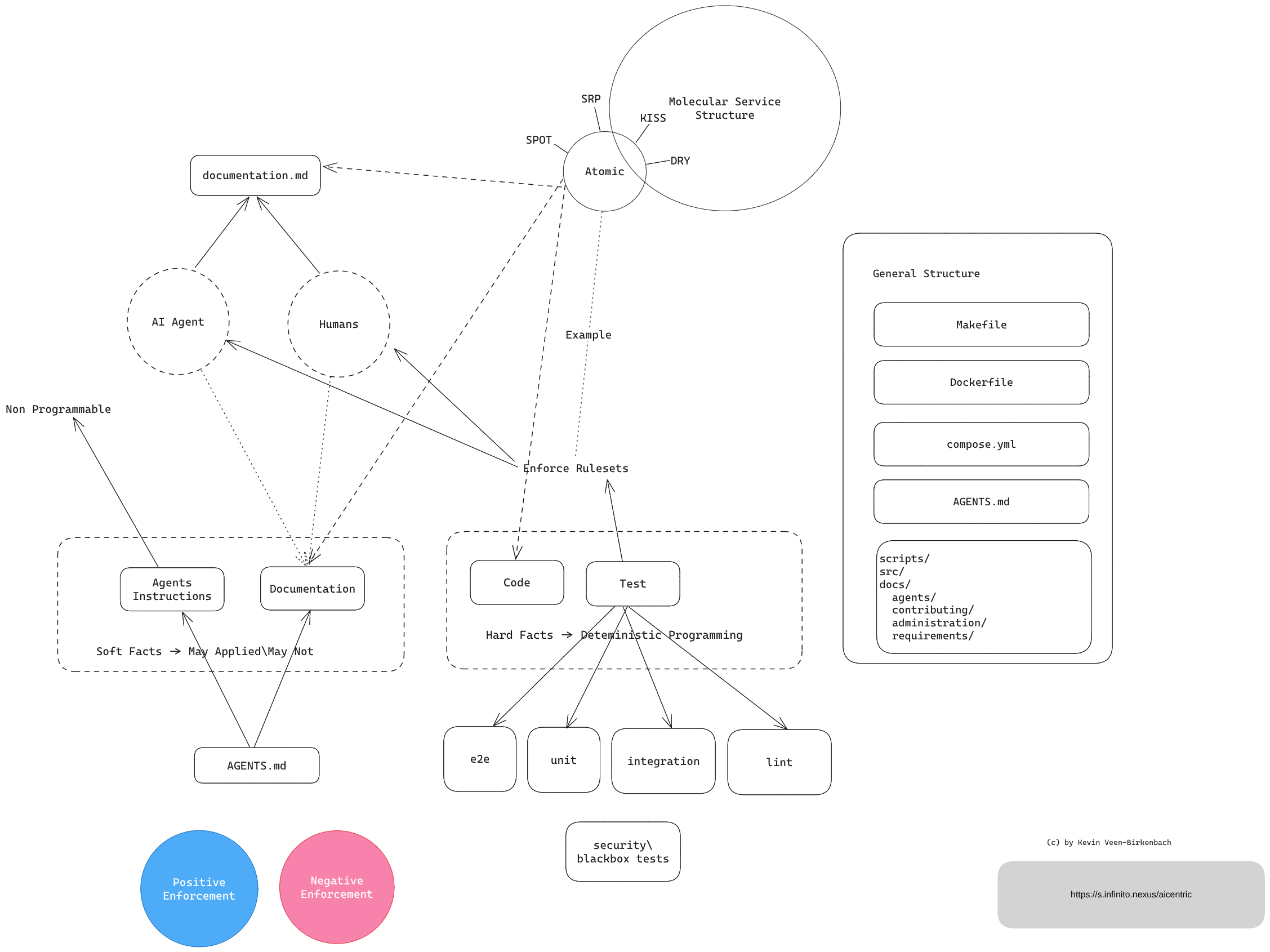
All of the above – model selection, effort tuning, the Cheatsheet workflow, the requirements document – only works well if one principle is kept in mind throughout: the concept of AI-Centric Development.
AI-Centric Development does not mean handing control to the model. It means the opposite: the AI is the tool, and the human is in charge. The agent executes, but the developer understands, decides and takes responsibility.
In practice, this has one concrete consequence for every contribution to Infinito.Nexus:
Code may only be committed if it is actually used – and every staged change must be inspected and understood by a human before the commit.
This means: before every git commit, go through the diff deliberately. Read what the agent has written. Understand why it is structured the way it is. If something is unclear, clarify it – either by asking the model to explain, or by working it out yourself. Do not merge code that you cannot account for.
This is not bureaucracy. It is the minimum required to keep the human in the loop. An agent that commits unchecked code is not a tool – it is a liability. The moment a developer stops understanding what is in the codebase, the project loses the ability to maintain, debug and evolve it independently.
The goal of AI-Centric Development is to move faster and stay in control – not one at the expense of the other. The model accelerates the work. The human ensures it is correct, intentional and understood.